Python 3.11: Better Error Messages
After the big parser improvement in python 3.10, the latest 3.11 release continues with a lot of work put into improving runtime error messages.
Python has always been friendly to beginners, but some of the error messages can be confusing. This has been one of the focus areas for the python core devs. We saw the first results in Python 3.10 and those improvements have carried on into py 3.11
The PEG parser in Python 3.10
The first step to better error messages was to change to a new parser. The parser is the part of the interpreter that reads the python source code and converts it into a structure called the "abstract syntax tree". If there are any syntax errors, then they are detected during the parsing phase.
Until Python 3.9, a type called LL(1) parser was used. We are not going to get into parsing techniques here, but suffice to say that LL(1) parsers are common and simpler to implement.
In Python 3.10 the parser was completely rewritten to use a type of parser called a Parsing Expression Grammar parser, or PEG parser for short. Using the PEG parser made it much easier to locate the actual place where an error occurs and give a better error message.
Let us take a look at an example. In the code below, the closing } of the dictionary is missing.
a = {
"name": "playful python",
"category": "programming"
def main():
print(a["name"], a["category"])
When you run this code in python 3.9 you will get the following syntax error
Traceback (most recent call last):
File "test.py", line 5
def main():
^
SyntaxError: invalid syntaxFrom the parser's perspective the error makes sense: It is currently expecting another key-value pair, or the close of the dict. When it encounters a def then that is an invalid value inside a dictionary and it throws an error there.
From the user's perspective though, this error is extremely confusing. The error is in the dict, but the error message is pointing at the function. A new programmer might be thinking something is wrong with the function and keep checking the function code over and over.
In Python 3.10, with the PEG parser, this is the error
Traceback (most recent call last):
File "test.py", line 1
a = {
^
SyntaxError: '{' was never closedVery clear and very direct. The programmer has no doubts what has to be fixed.
Improvements in Python 3.11
After the big parser improvement in python 3.10, the latest 3.11 release continues with a lot of work put into improving runtime error messages.
Take a look at this error message from Python 3.10. Can you figure out whats the problem?
Traceback (most recent call last):
File "util.py", line 7, in <module>
calc(parent_companies) * calc(child_companies)
File "util.py", line 2, in calc
return companies[0][1][0]
IndexError: tuple index out of range
At this point we know we got an index out of range error, but which of those indices was out of range? Further, we call the function twice, once with calc(parent_companies) and also with calc(child_companies) so which of those calls gave the error? We will need to do a bit of debugging to simply answer these basic questions.
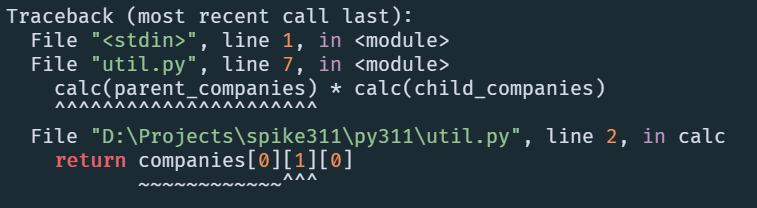
Here is the error message for the same code from Python 3.11
Traceback (most recent call last):
File "util.py", line 7, in <module>
calc(parent_companies) * calc(child_companies)
^^^^^^^^^^^^^^^^^^^^^^
File "util.py", line 2, in calc
return companies[0][1][0]
~~~~~~~~~~~~^^^
IndexError: tuple index out of rangeThe new error message points exactly where the index went out of range. Not only that, it also shows which call was executing in the parent function when this error occured! Very cool!
How does python do it?
It all comes back to the bytecode. If you are not familiar with the meaning of bytecode, take a look at the article below, where I explain it in detail.

When python is generating the bytecode, it used to store only the line number of the source associated to that bytecode. That has been expanded in python 3.11 to also store the column numbers.
The following code shows us this information
def calc(companies):
return companies[0][1][0]
import dis
for code in dis.Bytecode(calc):
print(code.opname,
code.positions.lineno,
code.positions.col_offset,
code.positions.end_col_offset)The output is
RESUME 1 0 0
LOAD_FAST 2 11 20
LOAD_CONST 2 21 22
BINARY_SUBSCR 2 11 23
LOAD_CONST 2 24 25
BINARY_SUBSCR 2 11 26
LOAD_CONST 2 27 28
BINARY_SUBSCR 2 11 29
RETURN_VALUE 2 4 29Apart from the first line, all the other bytecodes are for line 2 in the function ( return companies[0][1][0] ). However, the new column numbers distinguishes them. So when one of those BINARY_SUBSCR gives an error, python can point out in the traceback exactly which one of the three subscript operations gave the error.
Another nice improvement is identifying potential typos. Try running this code
import itertools
c = itertools.counter()and you will get this error
Traceback (most recent call last):
File "util.py", line 3, in <module>
c = itertools.counter()
^^^^^^^^^^^^^^^^^
AttributeError: module 'itertools' has no attribute 'counter'. Did you mean: 'count'?When accessing an invalid attribute from a module, python tries to see if it was a potential typo and suggests alternatives in the traceback error with "Did you mean: ..."
There is a nice optimisation here. In case the exception is handled somewhere, then the calculations to identify potential suggestion need not run. Only if the exception in unhandled and is printed to the screen will the suggestions be calculated. This way, regular exceptions that happen during the course of running the program do not get affected by any overhead.
Summary
The python core team is spending a lot of effort on better error messages, and I think that is a good thing. These kind of features are easy to overlook in favour of more flashy additions, but it helps so much in making python a welcoming language for beginners. It is nice to see error messages getting the attention they deserve.
Written by


