
I recently gave a talk at the local Chennai Python User Group about using the pyparsing library to parse files.
Here are the slides along with the commentary from the session. (Note that you need to be a subscriber to access the full presentation. Subscribing is free)
And if you are reading this in email, make sure you enable the "download pictures" setting to see the slides.

We start with what looks like a simple example: A CSV file. It contains three fields - Person, City and Country. We want to parse this file and extract the data from it.

Well that sounds pretty simple. We can just split the lines using .split("\n") and then extract the individual fields from the line by similarly splitting on the comma. Easy peasy!

But there is a problem. What if our data itself contains a comma? In the slide above, "Chennai, India" is the value of the Location column. How do we represent this kind of data?

The CSV format has a feature for this scenario. It allows us to wrap the data with double quotes. When we do that, we can have commas within the data and it will still be treated as a single field. We can even have newlines in the field (eg: addresses that have multiple lines).
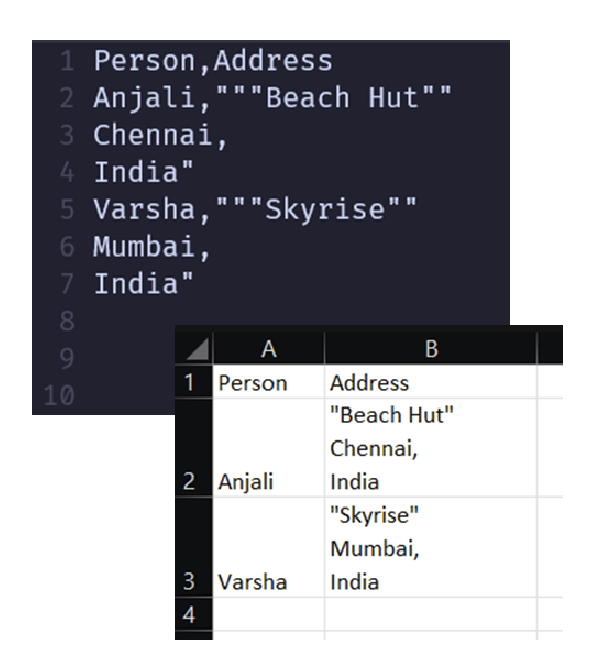
Here is a more complex CSV. You can see the Excel data and the equivalent CSV. Notice how we have double quotes as part of the content in a quoted field. You represent that in CSV by putting two double quotes one after another, "" which says that there is an actual quote mark here and we do not want to close the quoted field.

When we consider all this, our easy peasy solution doesn't work anymore. Splitting on the comma will split the field right in the middle. We need a more sophisticated solution that understands that the comma is not a separator when the field is wrapped with double quotes.

Well, maybe we can use a regular expression and provide a pattern that will detect this situation properly. Lets investigate.
This article is for subscribers only
To continue reading this article, just register your email and we will send you access.
Subscribe NowAlready have an account? Sign In