In the previous post we took a look into the different list data structures that python provides us. Today, we will do the same for dictionary. Unlike lists where python provides different list datatypes with different underlying implementations, dictionaries are implemented in just one way - using hash tables.
Python does provide many other mapping types that extend the behaviour of the vanilla dictionary and we'll cover these in the next article.
Dictionaries
In python, a dictionary is implemented using a hash table, so lets take a moment to understand how a hash table works.
In a hash table, first a chunk of memory is allocated, containing slots for various dict entries. At the start python dictionaries are initialised to hold eight items.
Actually, two chunks of memory are allocated. One contains a list of all the items in the dictionary as (hash, key, value) triplets. The second chunk of memory contains the actual hash table, storing the index where the data is located in the items list.

When you want to add a key-value pair to the dictionary, Python first takes the key and calculates its hash. The next thing to do is to find an empty slot in the dictionary. For that you just take the hash and modulo the size of the dictionary. Now you append the (hash, key, value) to the entries list and put its position index in the hash table.
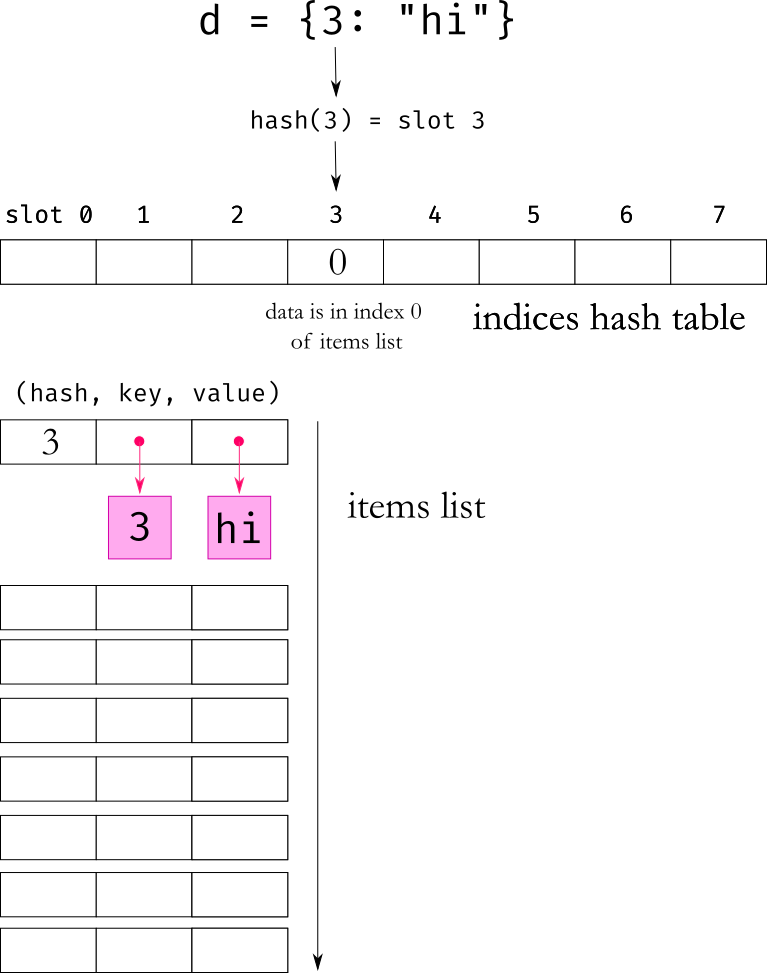
hash() function. For int and float the hash is based on the value. For most other objects the hash is based on the object id, which in CPython is the memory location where the object is stored. You can customise the way hash is calculated by overriding the __hash__ method.Once in a while, you may find that the slot in the hash table is already occupied. This is called a collision and happens when two keys hash values resolve to the same slot in the hash table. In that case, python uses a formula to find another spot in the hash table to check (In data structure terminology, this collision resolution strategy is called open addressing). If that spot is also taken, it repeats the formula to find another spot and keeps repeating this until it finds an empty spot.
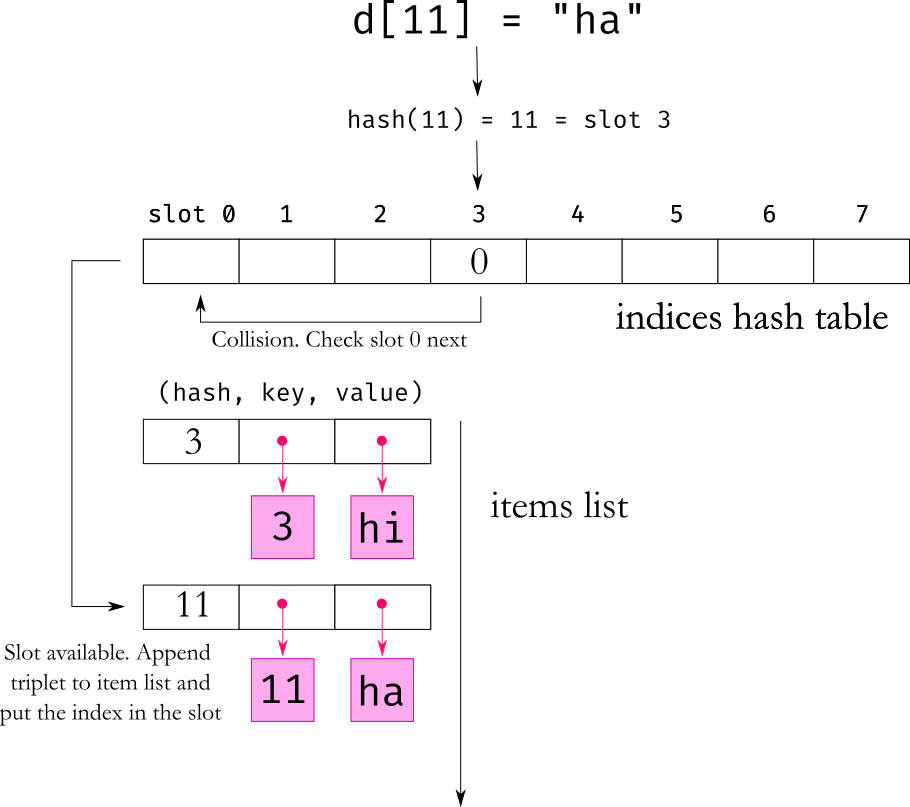
((5i + 1) % len). Assume we have a dictionary with space for 8 items. The hash resolved to slot 5 in the hash table, but that spot is occupied. Then i = 5 and len = 8 so Python will next try ((5 * 5 + 1) % 8) = slot 2. If that is also occupied, then the next slot to try will be ((5 * 2 + 1) % 8) = slot 3. If that is also occupied, following the formula, it will then try in order slots 0, 1, 6, 7 and 4 . As you can see, the formula will eventually try all the slots, but in a slightly haphazard sequence that minimises the chance of consecutive collisions. In practise, there is a small perturbabion that is also applied to mix up the sequence a little more.So adding an item to a dictionary is mostly a constant time operation, you just use the hash to calculate the target slot in the hash table and put the item there. But if the dictionary is almost full there will be a lot of collisions and the algorithm might have to scan a lot of spots searching for an available slot, which can significantly slow it down.
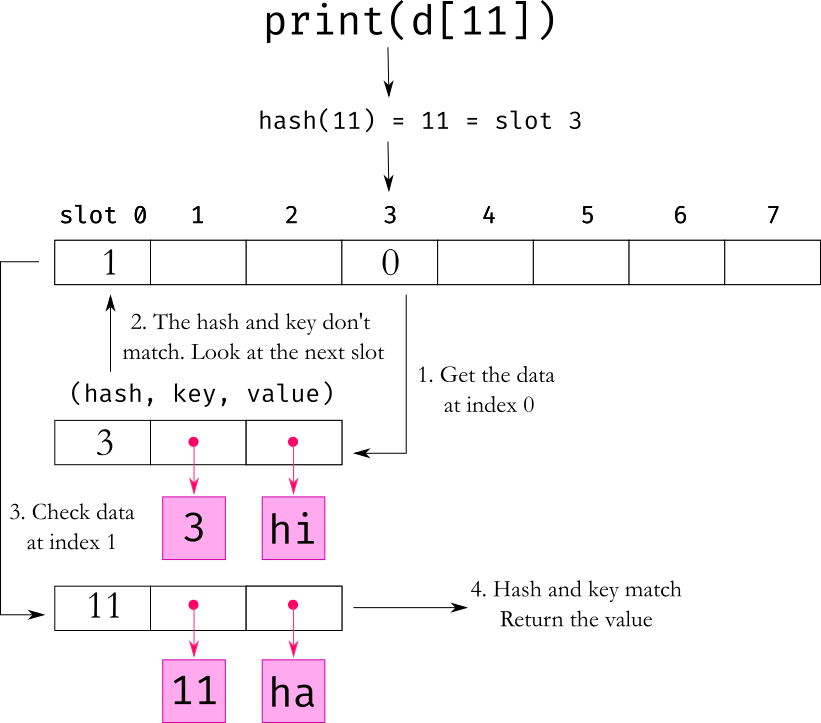
Reading the value is a similar operation - use the hash to find the target slot in the table and read out the value from there. As with setting a value, a complication happens when there is a collision, due to which the entry in that slot may not actually be the key that was requested but another entry. Python then follows the same collision formula to seek out the next slot and keeps following that strategy until it finds the location where the entry is located. This is why Python stores the hash and key along with the value. It can be used to confirm whether the item at that location is really the one that we are looking for.
Summary
Python dictionaries are implemented as hash tables. This makes it close to constant time to add an item to a dictionary or read a value from the dictionary. The dictionary is one of the most optimised data types in python, given that dictionaries are used for everything in python, from storing object attributes, managing global and local scopes and many other places in python internals.
Did you like this article?
If you liked this article, consider subscribing to this site. Subscribing is free.
Why subscribe? Here are three reasons:
- You will get every new article as an email in your inbox, so you never miss an article
- You will be able to comment on all the posts, ask questions, etc
- Once in a while, I will be posting conference talk slides, longer form articles (such as this one), and other content as subscriber-only