In previous articles we saw that python provides many different list options - you have the regular list which is implemented using arrays. You also have the collections.deque class which uses a doubly linked list. And there is the array module (and the superior numpy.array) that gives us the ability to embed the data in the array.
Unlike lists, dictionary implementations are all based on hash tables. However, Python does give us many different mapping types with different features, which we will explore in this article.
Sets
The most basic of the non-dict mapping type is the set. A set is like a dict that has only keys without values.
Why might you want to store only keys without values? Remember that the hash table implementation of dicts makes it very fast to look up whether a certain item is present in the data structure - you just take the hash() and go directly to that particular index. So you can use a set to keep track of whether some values are present or absent.
Take a look at this piece of code. It goes through a dataset and processes each line containing a file name and some content. It stores a list of file names that have been processed, and if a particular filename has already been processed previously then it skips that line.
def process(data):
filenames = []
for line in data:
name, content = line.split()
if name not in filenames:
process(name, content)
filenames.append(name)When you have a large amount of data, then this code will not perform well. This is because to check if an item is in a list, we have to go through every element in the list one by one and check. So the line if file not in filename: can get very slow once it starts to become really big. Each and every time it is going through the entire list.
This is the situation that is ideal for a set. Here is the code using set
def process(data):
filenames = set()
for line in data:
name, content = line.split()
if name not in filenames:
process(name, content)
filenames.add(name)The code is almost the same. But because we are using set, the check if file not in filenames: is very fast even when the set becomes huge.
Apart from this, the set also provides mathematical set operations which are not available on a dictionary - you can find the union, intersection and difference between two sets for example.
Another common use case for a set is to remove duplication from a list. Just like a dictionary, an item can be present only once in a set. Therefore taking a list and converting it to a set will end up keeping every value only once.
OrderedDict
Generally speaking, a dictionary is unordered. Because it uses a hash table, the first item might be stored somewhere in the middle of the hash table, the second item could be at the start and so on. This made the dictionary unordered.
There are many use cases where having an ordered mapping is useful and Python provided the collections.OrderedDict class that also kept track of the order of insertion.
However, in recent versions of python, the implementation of the dict was changed to use a separate index hash table and a separate entries list. Check out the previous article for the implementation details of a python dictionary
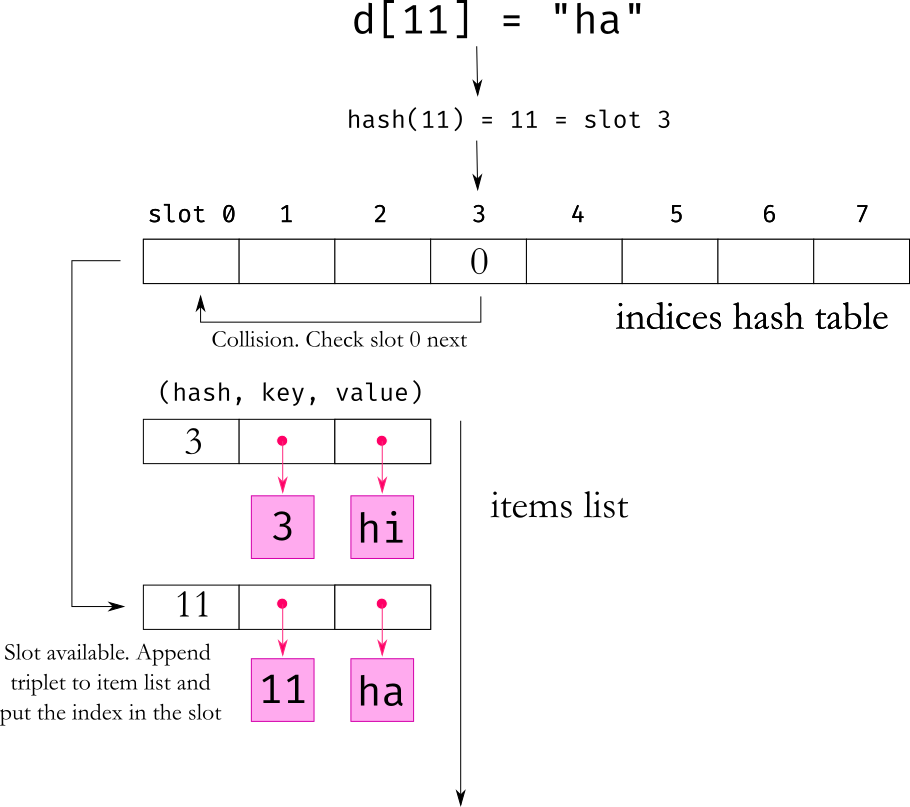
With this new design, the index hash table is unordered, but the entries list preserves the order in which entries were added into the dictionary. This makes the normal dictionary ordered by default and iterating a dictionary in a loop will give us every entry in the order it was put in. This makes collections.OrderedDict mostly unnecessary in the newer versions of Python.
One thing that the OrderedDict does have is a method move_to_end() to move an entry to either end (first or last) of the order. This makes it very useful for certain cases like for example a cache where you want to track how recently an item was updated
from collections import OrderedDict
class RecentlyUpdatedCache(OrderedDict):
def __setitem__(self, key, value):
super().__setitem__(key, value)
# last=False will move the item to the start of the order
self.move_to_end(key, last=False)
cache = RecentlyUpdatedCache()
cache['key1'] = 'value1'
cache['key2'] = 'value2'
cache['key3'] = 'value3'
cache['key2'] = 'value4'
# print the cache items in the order they were most recently updated
for item in cache.items():
print(item)
# ('key2', 'value4'), ('key3', 'value3'), ('key1', 'value1')defaultdict
The collections module also provides another dictionary variant called defaultdict.
When you access an item that doesn't exist in the dictionary, defaultdict will use a factory function to create an initial value and add it to the dictionary.
This is useful when the dictionary is going to be accumulating some value.
In the example below, we are going to count how many times each letter appears in a sentence. Normally, the first time we encounter a letter, we would need to add it to the dictionary. By using defaultdict(int) it will call the int() factory function (which returns 0) to set the initial value when the letter does not exist. This way, we avoid having a special case when the letter is added to the dictionary for the first time.
from collections import defaultdict
def counter(sentence):
count = defaultdict(int)
for letter in sentence:
count[letter] = count[letter] + 1
return countAlong the same lines, we can use defaultdict to build "multi-value" dictionaries where a key might have more than one value. Here, we use set as the factory function and each key will have a set of possible values (you can use a list instead if you want to preserve duplicate values).
from collections import defaultdict
query_string = "name=python&name=playful&type=website"
query = defaultdict(set)
for entry in query_string.split('&'):
key, value = entry.split('=')
query[key].add(value)ChainMap
The collections module comes with a third type of dictionary variant called the ChainMap. As the name implies, it is used to chain mulpitle dictionaries together.
Consider a configuration system, where there may be a global configuration, a local configuration and a user-level configuration. When we need to look up a configuration, we first see it there is any user-level value for it. If not, then we check in the local configuration, and finally in the global configuration.
This kind of lookup is easy to do with ChainMap
from collections import ChainMap
userconf = {'key1': 'user'}
localconf = {'key1': 'local', 'key2': 'local'}
globalconf = {'key1': 'global', 'key2': 'global', 'key3': 'global'}
config = ChainMap(userconf, localconf, globalconf)
print(config['key1']) # user
print(config['key2']) # local
print(config['key3']) # globalCounter
One of the features of the set data type is that each item can only be present once. What if we need to know how many times each item is present? In computer science terminology, a data structure that can preserve the count of duplicated items in a set is known as a "Bag" data type, or a "Multiset" data type.
At first glance, it seems like Python does not provide an inbuilt bag / multiset data type but if you look closely, you will find that it is present as the collections.Counter class. Although the class does not use the term Bag or Multiset, it performs the same role.
Consider the calculation of prime factorisation of a number. The prime factorisation of 120 is the multiset {2, 2, 2, 3, 5}. Here we do not care about order, the multiset {2, 3, 5, 2, 2} is the same multiset. The duplication is important though, {2, 3, 5} is a different multiset. These requirements make both list and set unsuitable, but Counter fits the bill.
def factorise_once(num):
for divisor in range(2, num+1):
if num % divisor == 0:
return divisor, num/divisor
def prime_factorisation(num):
factors = Counter()
while num != 1:
factor, num = factorise_once(num)
factors.update([factor])
return factors
print(prime_factorisation(120)) # Counter({2: 3, 3: 1, 5: 1})As we can see, Counter keeps track of the individual items, as well as how many times they are present.
In addition, Counter has a few more methods to make it more suitable for multiset operation. This includes features to add or subtract two Counter objects together, handling negative counts and so on. If you have been looking for a multiset data type in Python, then Counter is what you want.
Summary
In this article we took a look at the many different mapping data types that python provides apart from the regular dict. We looked at
setcollections.OrderedDictcollections.defaultdictcollections.ChainMapcollections.Counter
While set is a built in data type, all the others are in the collections module. As we can see, python comes with many different variations that we can take advantage of in the appropriate time in our code. We have seen in this article what features are provided by each of these types and when we may want to use each of them. Using these can literally make a lot of potentially complex code into simple one-liners.
Did you like this article?
If you liked this article, consider subscribing to this site. Subscribing is free.
Why subscribe? Here are three reasons:
- You will get every new article as an email in your inbox, so you never miss an article
- You will be able to comment on all the posts, ask questions, etc
- Once in a while, I will be posting conference talk slides, longer form articles (such as this one), and other content as subscriber-only